
Network theory is an important key to working in modern economies. It is possible to identify different types of networks:
- Informative networks are connections of information objects, like the network of citations between academic papers, world wide web, semantic networks, et cetera.
- Biological networks represent observable biological systems, like food web, protein interaction networks.
- Technological networks are designed typically for distribution of commodity and services and can be subdivided into infrastructure networks (internet, power grid, transportation networks) and temporary networks (ad hoc communication networks, sensor networks, autonomous vehicles).
Through the network, it is possible to map a wide range of aspects of life, like fifteenth Century Florentine Marriages, friendships in sports clubs, viral marketing strategies, et cetera.
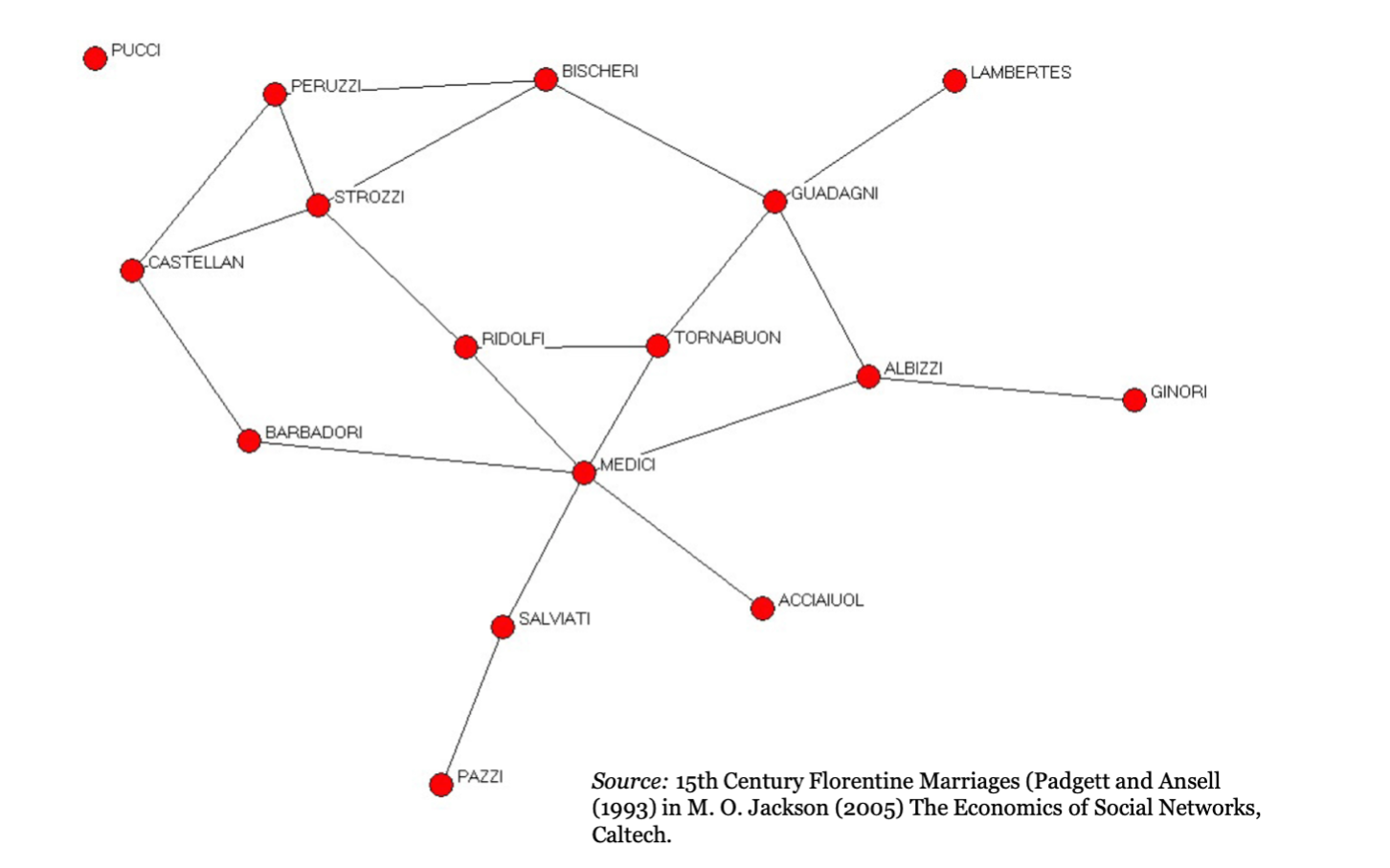
A Brief History of Network Studies
As curious as it may sound, network analysis could be born in 1736, in a little Russian city called Konisgsber (today known as Kaliningrad), thanks to Leonhard Euler. Before 1875, the city centre hosted a particular layout of seven bridges connecting the Kneiphof Island to the land areas, caught between the two branches of the Pregel River, as shown in the image below.
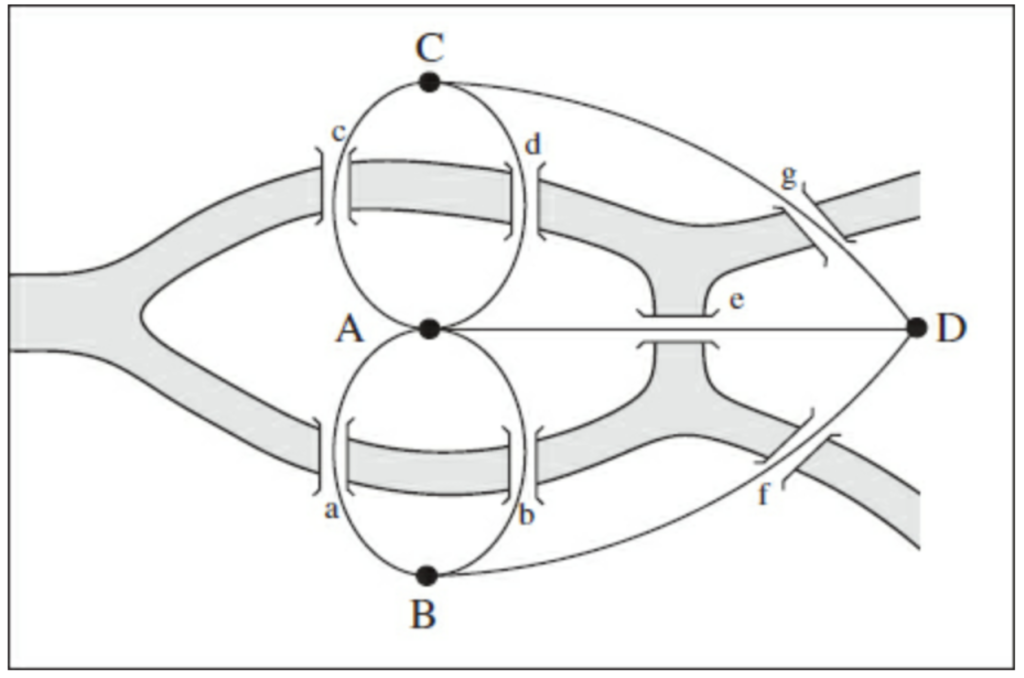
As Albert Lazlo Barabasi narrated in his non-fiction book “Linked” (2002), three hundred years ago, mathematicians were wondering whether it was possible to find a route around the layout that would let a person cross only once each bridge. Euler unknowingly started an immense branch of studies called branch theory by stating that the path does not exist, after having noticed that the route searched was a sequence of links connecting four nodes, i.e., a graph. The mathematic proof of the non-existence of the path is the following: nodes with an odd number of links must be a starting point or an ending point of the path. Moreover, a continuous path from the first to the seventh bridge should have just one starting point and a finishing point. As a consequence, such a path cannot exist on a graph with an odd number of links.
This short story tells a key message about network theory: networks and graphs are frameworks that make the world more understandable.
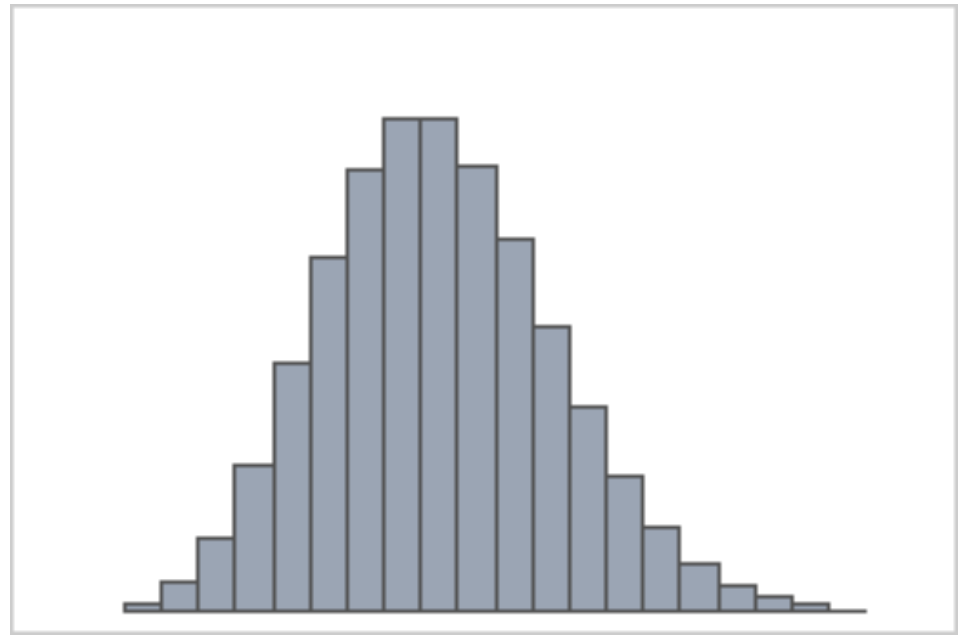
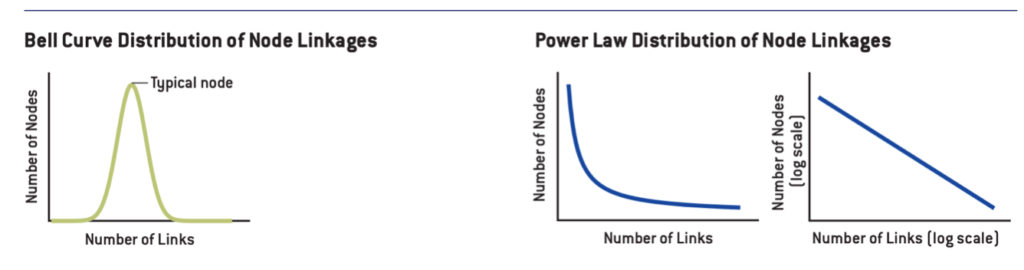
For the large part of graph theory history, the main idea about link creation was that it was utterly random introduced in 1959 by Erdos and Renyi was probably the most elegant and straightforward for the current knowledge of the period, why should have a node more possibilities to form a link than another one? However, Erdos friend Albert Einstein oppositely used to say “God does not play dice with the universe”. One of the consequences of this theory is that the number of edges that each node follows a Poisson distribution. The characteristic of a Poisson distribution is, as shown in the graph below, a remarked peak where most of the nodes have an average number of links, while on the extremes the number of nodes rapidly diminish.
Another interesting consequence of the assumed randomness of the graph is that given a node, the shortest path to any other node is a 10-basis logarithm of the norm, which turns out to be generally relatively small. For instance, species in food webs have averagely two links of separation, scientists studying different subjects are divided by just 5 connections, molecules in the cell are divided averagely by three chemical reactions, any of the trillions of web pages existing is separated by every other page by 19 links.
Are networks random? For instance, if the world wide web were a network randomly generated the probability of finding any page with more than five hundred links would tend to 0 (10^99), and if the network of Hollywood celebrities were random, it would be impossible that one actor would be few links far from any other actor. Nevertheless, according to the latest web survey (which covers around a fifth of the web), at least four hundred highly linked pages exists, and Rod Steiger, Donald Pleasance, Martin Sheen, Christopher Lee, Robert Mitchum and Charlton Heston boast a degree of separation from the rest of the whole Hollywood realm between 2,53 and 2,57.
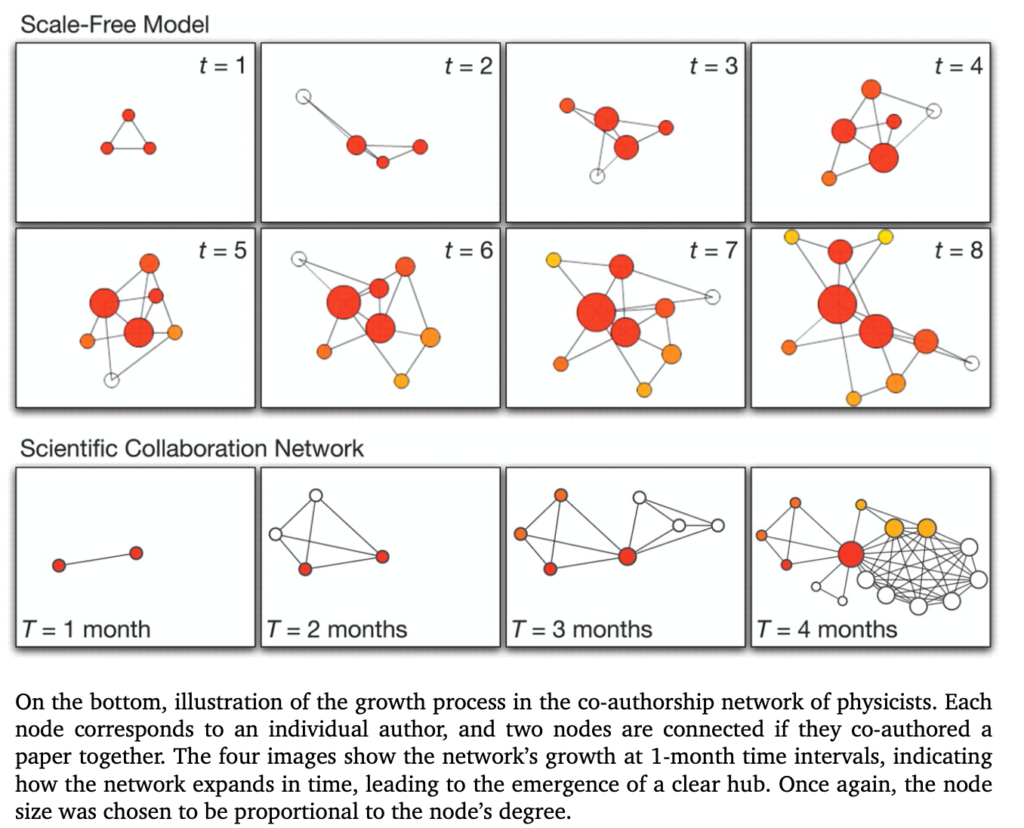
It was only in 1999 where the non-random nature of network found a unifying theory. It was noted that real networks tend to have two characteristics: preferential attachment and growth. Each network tends to begin from a small number of nodes, and afterwards, new nodes add up to the initial structure. Those latecomers do not choose random nodes. They tend to prefer the ones with a higher number of pre-existing links. This behaviour has become famous as the scale-free model, and it will be presented in the following pages.
Preferential attachment and growth undeniably do not tell the whole story: each node also has a concept called fitness: fitness is the ability to create connections relatively to everybody else in a given neighbourhood. It is well acknowledged that some companies are more able than others to make their customers more loyal, and some web services are more able to retain visitors. Defining this property helped the author to distinguish a part of the variance between winners and losers, like Google enormous ability in link-forming. Fitness is not overtaking but complementing the concept of preferential attachment and growth; it is one of the long series of consequences that the scale-free model brings with itself.
Scale Free Networks
As mentioned before, networks were supposed to be random until 1999, then Barabasi shifted the perspective by studying the World Wide Web. He found out that the probability that a web page has k edges is equal to , which is a power-law distribution and it breaks apart from the previous Poisson distribution predicted by random graph theory. Starting from this observation, Barabasi and his team started to notice that other networks followed a similar path, from cell to the social interactions, from protein to the internet (Barabasi, 2009).
Another exciting characteristic of scale-free networks si that the preferential mechanism works linearly: for instance, a new node has the double of the possibilities to connect to an existing node that has the double of the connection of an other close node.
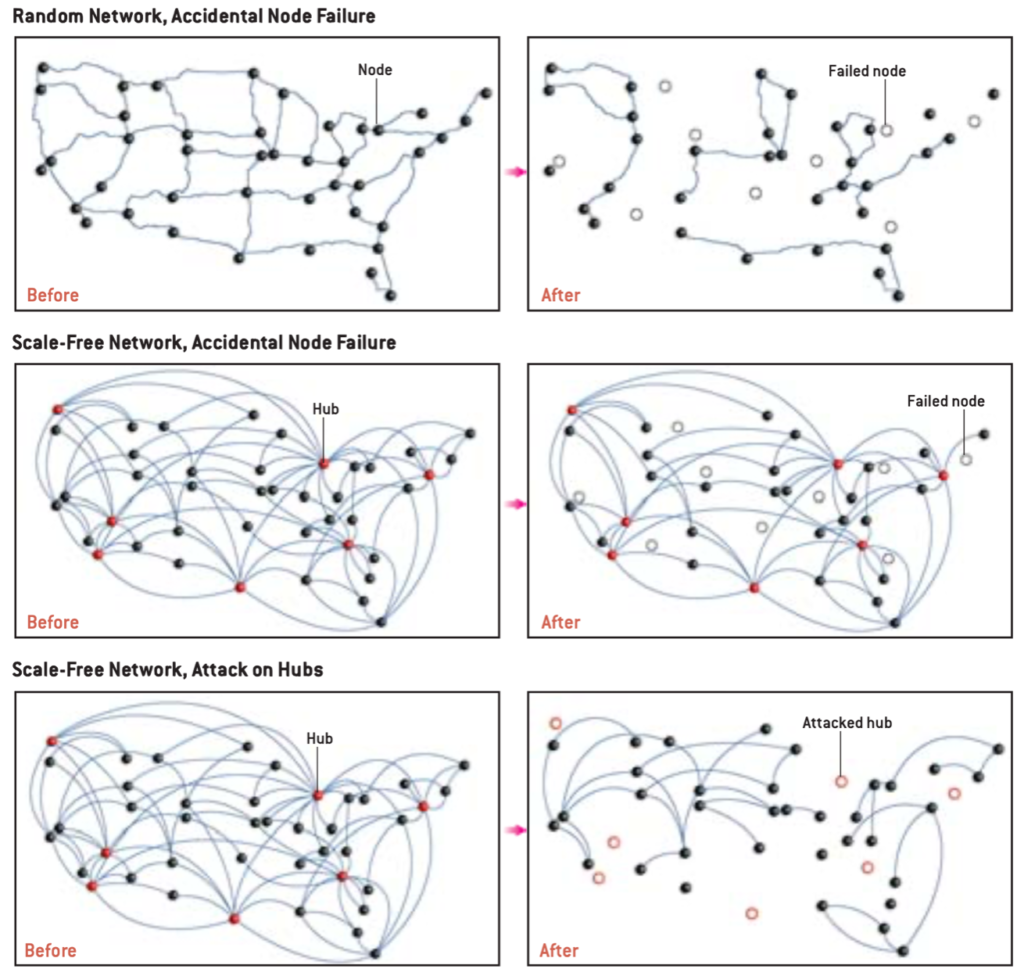
Scale-free modelling has a set of relevant characteristics that need to be taken into account: as first, they tend to be extremely resistant to failures, and a clear example of that is the fact that while internet hardware and software suffer thousand of issues around the globe, ordinary navigation is rarely affected. Even body cells often inherit a large number of mis-folded proteins and mutations without showing particular symptoms. The reason behind that is believed to be the following: while breaking random networks’ links may quickly turn into the fragmentation of the network in little islands if a critical node is targeted, when breaking a scale-free network’s link is not going to have critical consequences due to the connectedness of the main hubs.
A drawback of this feature is that the network tends to be extremely vulnerable: according to the authors’ simulation, the removal of a few hubs from the network turned into an extreme fragmentation. Immagine: scale free model network
Real-life implications of this dependence of hubs are numerous: computer networks are almost immune to accidental crashes but very vulnerable to hackers’ activities, thus eradicating viruses from computers results to be highly improbable. Taking into account medicine, vaccines tend to be more effective when targeting highly connected individuals and understanding cells’ network structure would help learn more about side effects of experimental drugs how to target cells’ hubs with drugs to guarantee high efficacy.
Another aspect to consider is that real-life offers also an excellent example of exceptions: for instance, according to the author, power grid in the US and highway systems are not scale-free networks, neither materials atoms composition, food webs and brain’s network seem to be scale-free network. Barabasi concludes that knowing whether a network is scale-free is essential, but also another factor has to be taken into account, like its diameter, its path length, et cetera.
Influences on Knowledge Management
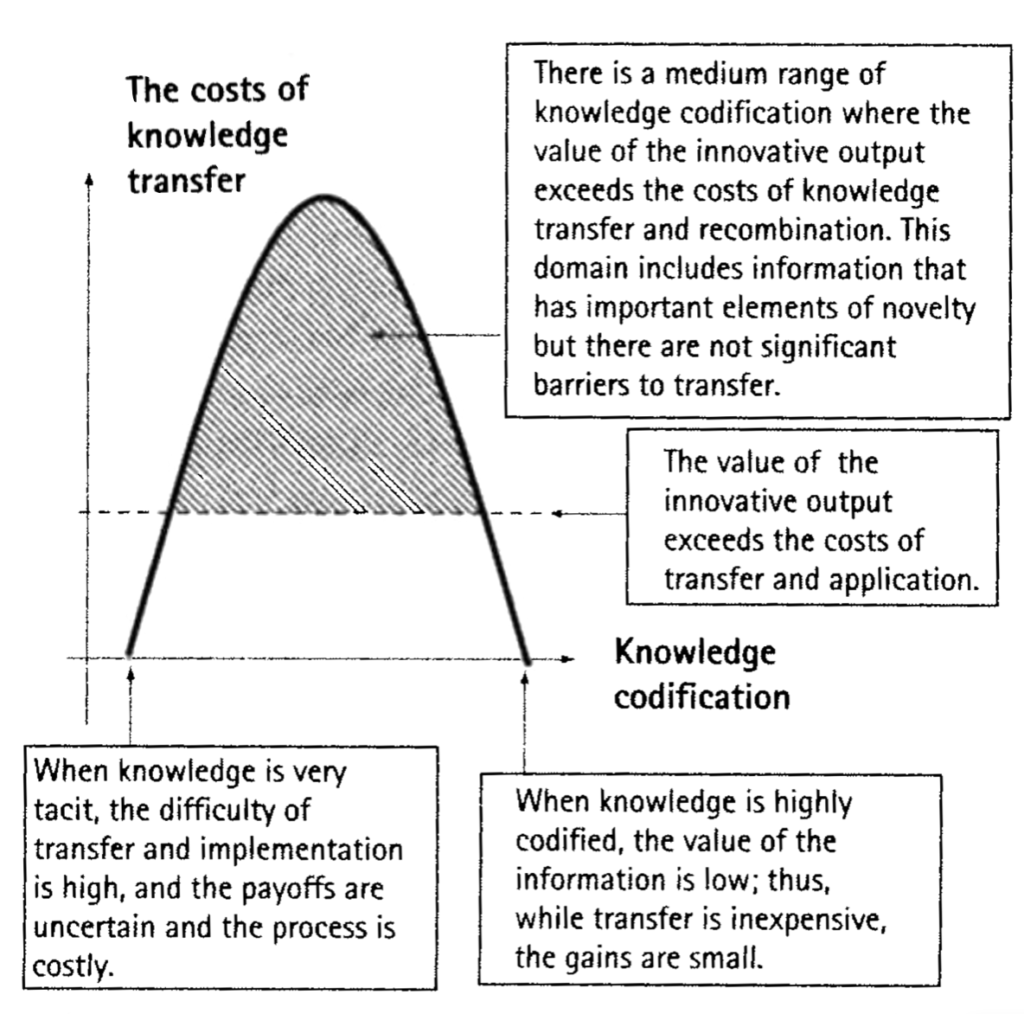
As we mentioned, also knowledge management is very important in modern’s economy, and not surprisingly, the reason behind the forming of the firms’ network is that they enable to enhance the knowledge transfer capability. According to Powell and Grodal (2005), knowledge sharing occurs in firms network in two cases in particular: when there is an exchange of complementary assets and when information is recombined, i.e., when existing problems, notions and solutions are turned together in something novel. Anticipating the following section, knowledge can be incredibly hard to transfer when it is implicit. Thus the development of a common ground of communication through an alliance may enhance the possibility of firms of exchange knowledge effectively. Specifically, there is a trade off, as shown in the image below.
Inkpen and Tsang (2005) identified in particular social capital dimension as an influencer of how knowledge is transferred between network nodes. It is crucial that, differently from what happens in other sections of the thesis, in this specific instance, different types of inter-firm network are considered together: intra-corporate networks, strategic alliances and industrial districts. The three realities are plotted on the following chart, having on the x and y axes respectively the verticality of the structure and the level of structuralisation.
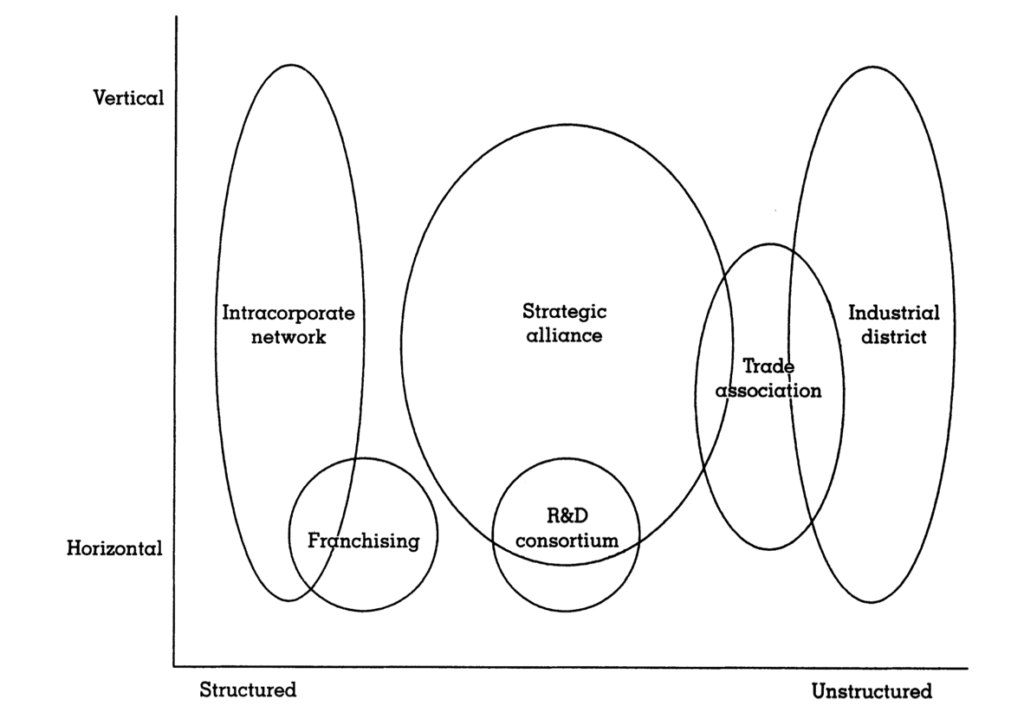
The author defines social capital as the group of resources coming from the network of relationships posses by each individual. Social capital has three sets of dimension: structural, cognitive and relational, that then can be broken down into different sub-dimensions, presented in the table below.
| Social Capital Dimension | Social Capital Sub-Dimension | Intracorporate Network | Strategic Alliance | Industrial District |
|---|---|---|---|---|
| Structural | Network ties | Fuzzy distinction between intramember and inter member ties | Intermember ties determining social ties within an alliance | Social ties as foundation for inter-member ties |
| Structural | Network configuration | Hierarchical, easy to establish connectivity between network members | Non hierarchical, possibility of exploiting structural hole positions | Non hierarchical and dense networks in a geographical region |
| Structural | Network stability | Stable membership | High rate of instability | Dynamic, with members joining and leaving the district |
| Cognitive | Shared Goals | Members working toward a common goal set by headquarters | Compatible goals but rarely common goals | None |
| Cognitive | Shared culture | Overarching corporate culture | Cultural compromise | Industry recipe |
| Relational | Trust | Little risk of opportunism | Significant risk of opportunism | Process based personal trust |
Each capital dimension directly creates or dismantles conditions for knowledge transfer, as shown in the following table.
| Social Capital Dimension | Social Capital Sub Dimension | Intracorporate Network | Strategic Alliance | Industrial District |
|---|---|---|---|---|
| Structural | Network ties | Personnel transfer between network members | Strong ties through repeated exchanges | Proximity to other members |
| Structural | Network configuration | Decentralisation of authority by headquarter | Multiple knowledge connections between partners | Weak ties and boundary spanners to maintain relationship with various cliques |
| Structural | Network stability | Low personnel turnover organisation ideal | Non competitive approach to knowledge transfer | Stable personal relationships |
| Cognitive | Shared Goals | Shared vision and collective goals | Goal clarity | Interaction logic derived from cooperation |
| Cognitive | Shared culture | Accomodation for local or national culture | Cultural diversity | Norms and rules to govern informal knowledge trading |
| Relational | Trust | Clear and transparent reward criteria to reduce mistrust among network members | Shadow of the future | Commercial transactions embedded in social ties |
The table helps the readers understand that in judging knowledge-sharing networks activities it is important to take into account the different social enablers that the network members may or may not have to share their knowledge.
Final factor considers in knowledge sharing among network nodes, as highlighted by Wang (2016), is the strength of the tie: average tie strength and knowledge creation seem to follow an inverted bell shape curve. The idea behind that is that additional ties enhance cultural diversity, but on the other side, it reaches a certain threshold where networks’ nodes are too link-minded. In other words, a network seems to be at its best knowledge-producing capability when it has a proper balance between exploitation and exploration component, which means that it has a proper balance of strong and weak ties. Added to that, in case of high tie strength, a less skewed network should achieve worse performance than a more skewed one because it still lacks a robust mixture of weak and strong ties (Wang, 2016).
That’s a brief excursus about what literature knows about networks, but how to put it in practice? Please look at this article, where I have shared how to create a network from basic data.
The publications cited in the article can be found here.
Leave a Reply